But rdtscp is serializing! No, it's not. Quoting the Intel Instruction Set Reference: "The RDTSCP instruction is not a serializing instruction, but it does wait until all previous instructions have executed and all previous loads are globally visible. But it does not wait for previous stores to be globally visible, and subsequent instructions may begin execution before the read operation is performed.", "The RDTSC instruction is not a serializing instruction. It does not necessarily wait until all previous instructions have been executed before reading the counter. Similarly, subsequent instructions may begin execution before the read operation is performed." So, the difference is in waiting for prior instructions to finish executing. Notice that even in the rdtscp case, execution of the following instructions may commence before time measurement is finished and data stores may be still pending. But, you may say, Intel in its "How to Benchmark Code Execution Times" document shows that using rdtscp is superior to rdstc. Well, not exactly. What they do show is that when a *single function* is considered, there are ways to measure its execution time with little to no error. This is not what Tracy is doing. In our case there is no way to determine absolute "this is before" and "this is after" points of a zone, as we probably already are inside another zone. Stopping the CPU execution, so that a deeply nested zone may be measured with great precision, will skew the measurements of all parent zones. And this is not what we want to measure, anyway. We are not interested in how a *single function* behaves, but how a *whole program* behaves. The out-of-order CPU behavior may influence the measurements? Good! We are interested in that. We want to see *how* the code is really executed. How is *stopping* the CPU to make a timer read an appropriate thing to do, when we want to see how a program is performing? At least that's the theory. And besides all that, the profiling overhead is now reduced. |
||
|---|---|---|
| capture | ||
| client | ||
| common | ||
| doc | ||
| extra | ||
| icon | ||
| imgui | ||
| imguicolortextedit | ||
| libbacktrace | ||
| manual | ||
| nfd | ||
| profiler | ||
| server | ||
| test | ||
| update | ||
| .appveyor.yml | ||
| .gitignore | ||
| AUTHORS | ||
| FAQ.md | ||
| LICENSE | ||
| NEWS | ||
| README.md | ||
| Tracy.hpp | ||
| TracyC.h | ||
| TracyClient.cpp | ||
| TracyClientDLL.cpp | ||
| TracyLua.hpp | ||
| TracyOpenGL.hpp | ||
| TracyVulkan.hpp | ||
Tracy Profiler
Tracy is a real time, nanosecond resolution frame profiler that can be used for remote or embedded telemetry of your application. It can profile CPU (C, C++11, Lua), GPU (OpenGL, Vulkan) and memory. It also can display locks held by threads and their interactions with each other.

The following compilers are supported:
- MSVC
- gcc
- clang
The following platforms are confirmed to be working (this is not a complete list):
- Windows (x86, x64)
- Linux (x86, x64, ARM, ARM64)
- Android (ARM, x86)
- FreeBSD (x64)
- Cygwin (x64)
- WSL (x64)
- OSX (x64)
Introduction to Tracy Profiler v0.2
New features in Tracy Profiler v0.3
New features in Tracy Profiler v0.4
New features in Tracy Profiler v0.5
High-level overview

Tracy is split into client and server side. The client side collects events using a high-efficiency queue and awaits for an incoming connection. The server part connects to client and receives collected data from the client, which is then reconstructed into a viewable timeline. The transfer is performed using a TCP connection.
Performance impact
To check how much slowdown is introduced by using Tracy, I have profiled etcpak, which is the fastest ETC texture compression utility there is. I used an 8192×8192 test image as input data and instrumented everything down to the 4×4 pixel block compression function (that's 4 million blocks to compress). It should be noted that Tracy needs to calibrate its internal timers at each run. This introduces a delay of 115 ms (on my machine), which is negligible when doing lengthy profiling runs, but it skews the results of etcpak timing. The following times have this delay subtracted, to give focus on zone collection impact, which is the thing that really matters here.
| Scenario | Zones | Clean run | Profiling run | Difference |
|---|---|---|---|---|
| Compression of an image to ETC1 format | 4194568 | 0.94 s | 1.003 s | +0.063 s |
| Compression of an image to ETC2 format, with mip-maps | 5592822 | 1.034 s | 1.119 s | +0.085 s |
In both scenarios the per-zone time cost is at ~15 ns. This is in line with the measured 8 ns single event collection time (each zone has to report start and end event).
Usage instructions
The user manual for Tracy is available at the following address. It provides information about the integration process, required code markup and so on.
Features
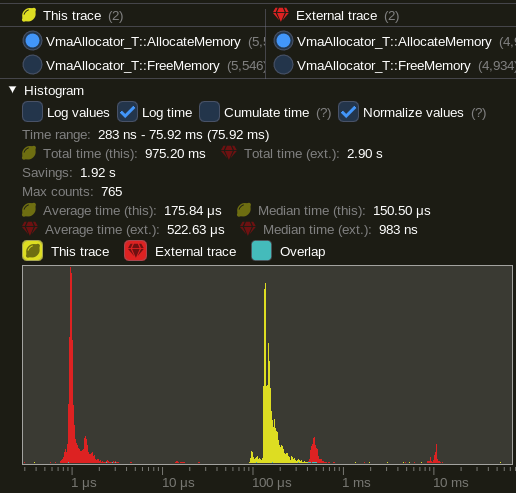
Histogram of function execution times

Comparison of two profiling runs
Marking locks

Plotting data

Message log
