Right now DWARFContext for DWO/DWP that is created is not thread safe.
Changed it so that thread safety is inherited from the main
binary DWARFContext.
For now, data location expression is hard coded to little endian. We are
going to support sanitizers on AIX which is big endian. Support big
endian too in the data location expression parser of llvm-symbolizer.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can use the shorter form. This patch replaces
llvm::support::endianness with llvm::endianness.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can directly get endianness from the llvm
namespace. We don't need to go through support.
Changed so that when Abbrev code is printed out for entry it is done in
the same
way as in Abbrev table.
Once letters are present in a hex number in abbrev table they will be
lower case,
and in the Entry upper case. Which makes FIleCheck Pattern recognition
fail.
Example in: llvm/test/tools/llvm-dwarfdump/X86/debug-names-misaligned.s
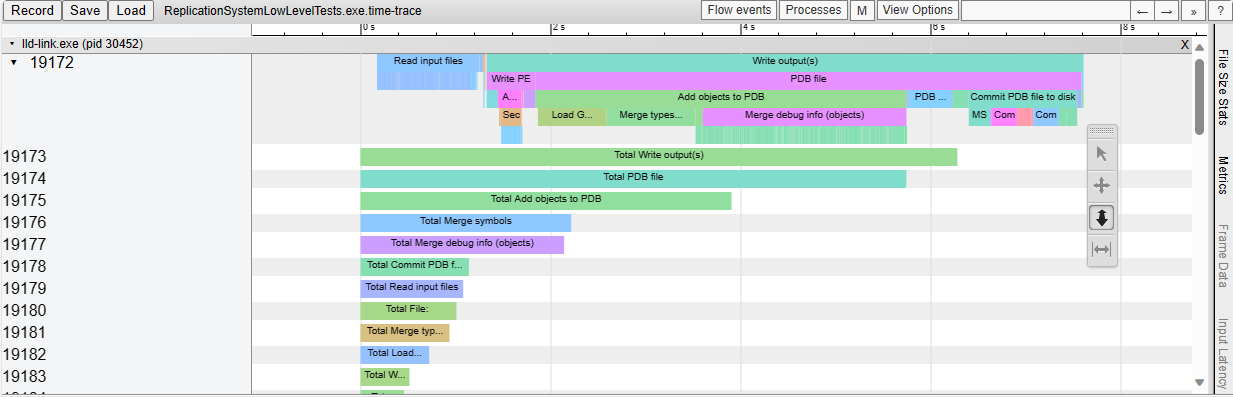
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
system_endianness() just returns llvm::endianness::native, a
compile-time constant equivalent to std::native in C++20. This patch
deprecates system_endianness() while replacing all invocations of
system_endianness() with llvm::endianness::native.
While we are at it, this patch replaces
llvm::support::endianness::{big,little} with
llvm::endianness::{big,little} in those statements that happen to call
system_endianness(). It does not go out of its way to replace other
occurrences of llvm::support::endianness::{big,little}.
Recent versions of GNU binutils starting from 2.39 support symbol+offset
lookup in addition to the usual numeric address lookup. This change adds
symbol lookup to llvm-symbolize and llvm-addr2line.
Now llvm-symbolize behaves closer to GNU addr2line, - if the value specified
as address in command line or input stream is not a number, it is treated as
a symbol name. For example:
llvm-symbolize --obj=abc.so func_22
llvm-symbolize --obj=abc.so "CODE func_22"
This lookup is now supported only for functions. Specification with
offset is not supported yet.
Differential Revision: https://reviews.llvm.org/D149759
Without this patch, we pass Endian as one of the parameters to the
constructor of DataExtractor. The problem is that Endian is of:
enum endianness {big, little, native};
whereas the constructor is expecting "bool IsLittleEndian". That is,
we are relying on an implicit conversion to convert big and little to
false and true, respectively.
When we migrate llvm::support::endianness to std::endian in future, we
can no longer rely on an implicit conversion because std::endian is
declared with "enum class". Even if we could, the conversion would
not be guaranteed to work because, for example, libcxx defines:
enum class endian {
little = 0xDEAD,
big = 0xFACE,
:
where big and little are not boolean values.
This patch fixes the problem by properly converting Endian to a
boolean value.
The `S_INLINEES` debug symbol is used to record all the functions that
are directly inlined within the current function (nested inlining is
ignored).
This change implements support for emitting the `S_INLINEES` debug
symbol in LLVM, and cleans up how the `S_INLINEES` and `S_CALLEES` debug
symbols are dumped.
To make DWARFDebugAbbrev more amenable to error-handling, I would like
to change the return type of DWARFDebugAbbrev::parse from `void` to
`Error`. Users of DWARFDebugAbbrev can consume the error if they want to
use all the valid DWARF that was parsed (without worrying about the
malformed DWARF) or stop when the parse fails if the use case needs to
be strict.
This also will bring the LLVM DWARFDebugAbbrev interface closer to
LLDB's which opens up the opportunity for LLDB adopt the LLVM
implementation with minimal changes.
Extend llvm-objdump to show CO-RE relocations when `-r` option is
passed and object file has .BTF and .BTF.ext sections.
For example, the following C program:
#define __pai __attribute__((preserve_access_index))
struct foo { int i; int j;} __pai;
struct bar { struct foo f[7]; } __pai;
extern void sink(void *);
void root(struct bar *bar) {
sink(&bar[2].f[3].j);
}
Should lead to the following objdump output:
$ clang --target=bpf -O2 -g t.c -c -o - | \
llvm-objdump --no-addresses --no-show-raw-insn -dr -
...
r2 = 0x94
CO-RE <byte_off> [2] struct bar::[2].f[3].j (2:0:3:1)
r1 += r2
call -0x1
R_BPF_64_32 sink
exit
...
More examples could be found in unit tests, see BTFParserTest.cpp.
To achieve this:
- Move CO-RE relocation kinds definitions from BPFCORE.h to BTF.h.
- Extend BTF.h with types derived from BTF::CommonType, e.g.
BTF::IntType and BTF::StrutType, to allow dyn_cast() and access to
type additional data.
- Extend BTFParser to load BTF type and relocation data.
- Modify llvm-objdump.cpp to create instance of BTFParser when
disassembly of object file with BTF sections is processed and `-r`
flag is supplied.
Additional information about CO-RE is available at [1].
[1] https://docs.kernel.org/bpf/llvm_reloc.html
Depends on D149058
Differential Revision: https://reviews.llvm.org/D150079
ObjectiveC has its own extra accelerator table entries that are helpful for the
debugger. This patch relaxes the DWARFVerifier so that it accepts those in DWARF
5's debug_names.
Differential Revision: https://reviews.llvm.org/D159471
The DWARFLinker library has code to identify ObjC selector names, which is used
by the debug linker to generate accelerator table entries. In the future, we
would like the DWARF verifier to also have access to such code, so that it can
identify these names when verifying accelerator tables (e.g. debug_names).
This patch follows the same intent of D155723, where we also moved code
generating simplified template names.
Since this is moving code around and changing the log, we also replace raw
pointer manipulation with the more expressive
StringRef::{drop_front,take_front,...} methods.
We also change a test so that it verifies its output, and that requires having
dsymutil not write to stdout.
Differential Revision: https://reviews.llvm.org/D158980
llvm-gsymutil uses a DWARFContext from multiple threads as it parses each compile unit. As it finds issues it might end up dumping a DIE to an output stream which can cause accesses to the DWARFContext from multiple threads. In llvm-gsymutil it can end up dumping a DIE from multiple threads into thread specific stream which was causing DWARFContext::getTUIndex() to be called and can crash the process.
This fix puts a recursive mutex into the DWARFContext class and makes most APIs threadsafe for access. Many of the methods in DWARFContext will check if a member variable has been filled in yet, and parse what is needed and populate a member variagle with the results. Now a mutex protects these functions.
Differential Revision: https://reviews.llvm.org/D157459
The CodeView `S_ARMSWITCHTABLE` debug symbol is used to describe the layout of a jump table, it contains the following information:
* The address of the branch instruction that uses the jump table.
* The address of the jump table.
* The "base" address that the values in the jump table are relative to.
* The type of each entry (absolute pointer, a relative integer, a relative integer that is shifted).
Together this information can be used by debuggers and binary analysis tools to understand what an jump table indirect branch is doing and where it might jump to.
Documentation for the symbol can be found in the Microsoft PDB library dumper: 0fe89a942f/cvdump/dumpsym7.cpp (L5518)
This change adds support to LLVM to emit the `S_ARMSWITCHTABLE` debug symbol as well as to dump it out (for testing purposes).
Reviewed By: efriedma
Differential Revision: https://reviews.llvm.org/D149367
If llvm-symbolizer finds a malformed command, it echoes it to the
standard output. New versions of binutils (starting from 2.39) allow to
specify an address by a symbols. Implementation of this feature in
llvm-symbolizer makes the current reaction on invalid input
inappropriate. Almost any invalid command may be treated as a symbol
name, so the right reaction should be "symbol not found" in such case.
The exception are commands that are recognized but have incorrect
syntax, like "FILE:FILE:". The utility must produce descriptive
diagnostic for such input and route it to the stderr.
This change implements the new reaction on invalid input and is a
prerequisite for implementation of symbol lookup in llvm-symbolizer.
Differential Revision: https://reviews.llvm.org/D157210
D152495 makes clang warn on unused variables that are declared in conditions like `if (int var = init) {}`
This patch is an NFC fix to suppress the new warning in llvm,clang,lld builds to pass CI in the above patch.
Differential Revision: https://reviews.llvm.org/D158016
This reverts commit 8d0c3db388143f4e058b5f513a70fd5d089d51c3.
Causes crashes, see comments in https://reviews.llvm.org/D149367.
Some follow-up fixes are also reverted:
This reverts commit 636269f4fca44693bfd787b0a37bb0328ffcc085.
This reverts commit 5966079cf4d4de0285004eef051784d0d9f7a3a6.
This reverts commit e7294dbc85d24a08c716d9babbe7f68390cf219b.
The CodeView `S_ARMSWITCHTABLE` debug symbol is used to describe the layout of a jump table, it contains the following information:
* The address of the branch instruction that uses the jump table.
* The address of the jump table.
* The "base" address that the values in the jump table are relative to.
* The type of each entry (absolute pointer, a relative integer, a relative integer that is shifted).
Together this information can be used by debuggers and binary analysis tools to understand what an jump table indirect branch is doing and where it might jump to.
Documentation for the symbol can be found in the Microsoft PDB library dumper: 0fe89a942f/cvdump/dumpsym7.cpp (L5518)
This change adds support to LLVM to emit the `S_ARMSWITCHTABLE` debug symbol as well as to dump it out (for testing purposes).
Reviewed By: efriedma
Differential Revision: https://reviews.llvm.org/D149367
llvm-gsymutil would emit errors about address ranges for DW_TAG_inlined_subroutine DIEs whose address range didn't exist in the parent inline information. When a DW_TAG_subprogram DIE has more than one address range with a DW_AT_ranges attribute, we emit multiple FunctionInfo objets, one for each range of a function. When we parsed the inline information, it might have inline contribution that appear in any of the function's ranges, and if we were parsing the first range of a function, all inline entries that appeared in other valid ranges of the functions would end up emitting error messages. This patch fixes this by always passing down the full list of ranges, even if they aren't being used in the parse of the information. This eliminates reporting of errors when we shouldn't have been emitting error messages. Added a test to track this and ensure this doesn't regress.
Also we don't warn if we end up with empty inline information if the only top level inline function have been elided where the high and low PC values are the same which indicates that the inline function was elided.
Differential Revision: https://reviews.llvm.org/D157669
D155723 changed the return type of getNames to a SmallVector of a different
size. However, it failed to also update the declaration of the variable that is
returned in such function.
Differential Revision: https://reviews.llvm.org/D157881
LLDB can benefit from having the base name of functions (i.e. without any
template parameters) as an entry into accelerator tables pointing back in the
DIE for the corresponding function specialization. In fact, some LLDB
functionality is only possible when those entries are present.
The DWARFLinker has been adding such entries for a while now, both with
apple_names and with debug_names. However, this has two side effects:
1. Some LLDB functionality is only possible when dsym bundles are present (i.e.
the linker touched the debug info).
2. The DWARFVerifier doesn't accept debug_name sections created by the linker,
as such names are (usually) neither the AT_name nor the AT_linkage_name of the
DIE.
Based on recent discussion [1], and because the DWARF 5 spec says that:
> A producer may choose to implement additional rules for what names are placed
> in the index
This patch relaxes the checks on the verifier to allow for simplified template
names in the accelerator table. To do so, we move some helper functions from
DWARFLinker into the core lib debug info. This addresses the point 2) above.
This patch also enables addressing point 1) in the future, since the helper
function is now visible to other parts of LLVM.
[1]: https://github.com/llvm/llvm-project/issues/58362
Differential Revision: https://reviews.llvm.org/D155723
This reverts commit a5fe6c7f5e2d1d265bd7c312ef55259fee7a68f9.
This change is causing problems with Windows build bots due to a hanging zombie llvm-symbolizer.exe process.
If llvm-symbolizer finds a malformed command, it echoes it to the
standard output. New versions of binutils (starting from 2.39) allow to
specify an address by a symbols. Implementation of this feature in
llvm-symbolizer makes the current reaction on invalid input
inappropriate. Almost any invalid command may be treated as a symbol
name, so the right reaction should be "symbol not found" in such case.
The exception are commands that are recognized but have incorrect
syntax, like "FILE:FILE:". The utility must produce descriptive
diagnostic for such input and route it to the stderr.
This change implements the new reaction on invalid input and is a
prerequisite for implementation of symbol lookup in llvm-symbolizer.
Differential Revision: https://reviews.llvm.org/D157210
This patch removes two log messages that were causing noisy output:
- when we have a zero sized symbol that gets removed in favor of something with a size or with debug info
- when an inlined function's address range has the same high and low pc, don't emit an error message as this is a common technique to indicate a function has been stripped or is no longer present.
Differential Revision: https://reviews.llvm.org/D156834
The GSYM code alwasy logging to streams even in quiet mode. When in quiet mode we would use the "nulls()" stream to avoid logging to the terminal, but this still caused logging functions to be called on DWARFDie objects and other messages which were quite expensive and not needed if we weren't logging anything. This patch switches some logs in performant areas to be "raw_ostream *" values and if the ostream pointer is NULL, then we don't call the expensive logging functions on DWARFDie and other objects which will improve performance.
Differential Revision: https://reviews.llvm.org/D157466
llvm-gsymutil was maintaining an address ranges collection behind a mutex and having the multi-threaded code access this and hold the mutex was causing slowdown when converting DWARF to GSYM. This patch does the following:
- removes the "Ranges" variable from the GsymCreator and any functions and places that used it
- clients don't try to detect if a function has been added for an address range, we now remove any inferior copies of information in the GsymCreator::finalize() routine as was done before, we just have more items to remove, though performance is greator due to less mutex thread locking
- after I started adding all of the inferior funtion info objects the previous patch that tried to remove infrior debug info had bugs in it, so I replace the removeIfBinary() function in GsymCreator with a more efficient and easier to debug way to do things which copies items from the GsymCreator::Funcs into a new vector of FunctionInfo objects and then replaces GsymCreator::Funcs at the end.
- Sorting of FunctionInfo objects has been modified to also compare InlineInfo objects. We found cases where LTO was ruining inline function address ranges and we ended up with a variety of FunctionInfo objects for the same range that had varying amounts of valid debug info. This patch now ensure that two function info objects with different inline info for the same function address range, the best one will be picked to ensure the greatest fidelity.
- If we detect that a DW_TAG_subprogram has inline functions and after parsing it, we don't end up with any valid inline information, we set the optional to std::nullopt to avoid emitting empty inline information and wasting space.
My tests show a 200% perf increase on M1 macs and a 100% performance increase on linux machines for the same complex large DWARF input binary.
Differential Revision: https://reviews.llvm.org/D156773
If a function contains inline function ranges whose address ranges are not contained in the parent scope, then emit an error message and omit them from the final GSYM. Prior to this we would only test if an inline function's address range was within the concrete function's ranges. If we ran into a case where the inline range was within the function's ranges, but not within one of the parent inline function's ranges, then we would fail to produce a GSYM file and exit with an error.
The current code will emit full details on invalid inline ranges as they are being parsed and will omit any bad ranges from the final GSYM file.
Differential Revision: https://reviews.llvm.org/D155254
Following recent changes switching from xxh64 to xxh32 for better
hashing performance (e.g., D154813). I am not familiar with this use
case, but this change will ensure that the lld executable doesn't need
xxHash64 after wasm-ld migrates.
The value to be formatted here, Val, is an int64_t which cannot be
formatted using %x. This commit adjusts all misuses I was able to find
in the llvm-dwarfdump project.
Failing tests in https://reviews.llvm.org/D153800 lead to the discovery
and analysis of this issue.
Differential Revision: https://reviews.llvm.org/D155093
"BTF" is a debug information format used by LLVM's BPF backend.
The format is much smaller in scope than DWARF, the following info is
available:
- full set of C types used in the binary file;
- types for global values;
- line number / line source code information .
BTF information is embedded in ELF as .BTF and .BTF.ext sections.
Detailed format description could be found as a part of Linux Source
tree, e.g. here: [1].
This commit modifies `llvm-objdump` utility to use line number
information provided by BTF if DWARF information is not available.
E.g., the goal is to make the following to print source code lines,
interleaved with disassembly:
$ clang --target=bpf -g test.c -o test.o
$ llvm-strip --strip-debug test.o
$ llvm-objdump -Sd test.o
test.o: file format elf64-bpf
Disassembly of section .text:
<foo>:
; void foo(void) {
r1 = 0x1
; consume(1);
call -0x1
r1 = 0x2
; consume(2);
call -0x1
; }
exit
A common production use case for BPF programs is to:
- compile separate object files using clang with `-g -c` flags;
- link these files as a final "static" binary using bpftool linker ([2]).
The bpftool linker discards most of the DWARF sections
(line information sections as well) but merges .BTF and .BTF.ext sections.
Hence, having `llvm-objdump` capable to print source code using .BTF.ext
is valuable.
The commit consists of the following modifications:
- llvm/lib/DebugInfo/BTF aka `DebugInfoBTF` component is added to host
the code needed to process BTF (with assumption that BTF support
would be added to some other tools as well, e.g. `llvm-readelf`):
- `DebugInfoBTF` provides `llvm::BTFParser` class, that loads information
from `.BTF` and `.BTF.ext` sections of a given `object::ObjectFile`
instance and allows to query this information.
Currently only line number information is loaded.
- `DebugInfoBTF` also provides `llvm::BTFContext` class, which is an
implementation of `DIContext` interface, used by `llvm-objdump` to
query information about line numbers corresponding to specific
instructions.
- Structure `DILineInfo` is modified with field `LineSource`.
`DIContext` interface uses `DILineInfo` structure to communicate
line number and source code information.
Specifically, `DILineInfo::Source` field encodes full file source code,
if available. BTF only stores source code for selected lines of the
file, not a complete source file. Moreover, stored lines are not
guaranteed to be sorted in a specific order.
To avoid reconstruction of a file source code from a set of
available lines, this commit adds `LineSource` field instead.
- `Symbolize` class is modified to use `BTFContext` instead of
`DWARFContext` when DWARF sections are not available but BTF
sections are present in the object file.
(`Symbolize` is instantiated by `llvm-objdump`).
- Integration and unit tests.
Note, that DWARF has a notion of "instruction sequence".
DWARF implementation of `DIContext::getLineInfoForAddress()` provides
inexact responses if exact address information is not available but
address falls within "instruction sequence" with some known line
information (see `DWARFDebugLine::LineTable::findRowInSeq()`).
BTF does not provide instruction sequence groupings, thus
`getLineInfoForAddress()` queries only return exact matches.
This does not seem to be a big issue in practice, but output
of the `llvm-objdump -Sd` might differ slightly when BTF
is used instead of DWARF.
[1] https://www.kernel.org/doc/html/latest/bpf/btf.html
[2] https://github.com/libbpf/bpftool
Depends on https://reviews.llvm.org/D149501
Reviewed By: MaskRay, yonghong-song, nickdesaulniers, #debug-info
Differential Revision: https://reviews.llvm.org/D149058
This extends DWARFDebugLine to properly parse line number programs with
maximum_operations_per_instruction > 1 for VLIW targets.
No functions that use that parsed output to retrieve line information
have been extended to support multiple op-indexes. This means that when
retrieving information for an address with multiple op-indexes, e.g.
when using llvm-addr2line, the penultimate row for that address will be
used, which in most cases is the row for the second largest op-index.
This will be addressed in further changes, but this patch at least
allows us to correctly parse such line number programs, with a warning
saying that the line number information may be incorrect (incomplete).
Reviewed By: StephenTozer
Differential Revision: https://reviews.llvm.org/D152536
This is a preparatory patch for extending DWARFDebugLine to properly
parse line number programs with maximum_operations_per_instruction > 1
for VLIW targets.
Add some scaffolding for handling op-index in line number programs, and
add printouts for that in the table. As this affects a lot of tests,
this is done in a separate commit to get a cleaner review for the actual
op-index implementation.
Verbose printouts are not present in many tests, and adding op-index to
those will require a bit more code changes, so that is done in the
actual implementation patch.
Reviewed By: StephenTozer
Differential Revision: https://reviews.llvm.org/D152535
This revision implement new mechanism for DWARFRewriter.
In the new mechanism, we adopt the same way with DWARFLinker did.
By parsing Debug information into IR, we are allowed to handle debug information more flexible.
Now the debug information updating process relies on IR and IR will be written out to binary once the updating finished.
A new class was added: DIEBuilder. This class is responsible for parsing debug information and raising it to the IR level.
This class is also used to write out the .debug_info and .debug_abbrev sections.
Since we output brand new Abbrev section we won't need to always convert low_pc/high_pc into ranges.
When conversion does happen we can also remove low_pc entry.
Reviewed By: maksfb, ayermolo
Differential Revision: https://reviews.llvm.org/D130315
This reverts commit 460a2244430fae192298a5fd9fa2a269e540e8c1.
It breaks building on macOS, and it was landed with a review URL
pointing to some Facebook-internal service.
Also reverts a bunch of follow-ups:
Revert "[BOLT][DWARF] Don't check string offsets"
This reverts commit f9d6f48c8bf5acaac07502403c41cf0b0d89c8d2.
Revert "[BOLT][DWARF] Change to process and write out TUs first then CUs in batches"
This reverts commit 88e95c1e4bb6e2ad3bfd185b96341ad5c09eff6b.
Revert "[BOLT][DWARF] Output DWO files as they are being processed"
This reverts commit 46ca2e3fcd419b1246357ed3b9cd36630f16e64d.
Revert "[BOLT][DWARF] Don't check string offsets"
This reverts commit cfe4a4b04f219a9dbb4e3fc01883437b6ff0e702.
Revert "[BOLT][DWARF] Numerous fixes for a new DWARFRewriter"
This reverts commit 2701a661daa393ad5901ac88d420d7aa931eda0d.
Summary:
This revision implement new mechanism for DWARFRewriter.
In the new mechanism, we adopt the same way with DWARFLinker did.
By parsing Debug information into IR, we are allowed to handle debug information more flexible.
Now the debug information updating process relies on IR and IR will be written out to binary once the updating finished.
A new class was added: DIEBuilder. This class is responsible for parsing debug information and raising it to the IR level.
This class is also used to write out the .debug_info and .debug_abbrev sections.
Since we output brand new Abbrev section we won't need to always convert low_pc/high_pc into ranges.
When conversion does happen we can also remove low_pc entry.
Differential Revision: https://phabricator.intern.facebook.com/D39484421
Tasks: T117448832
The symbolizer markup syntax is structured such that fields require only
previous fields for their interpretation; this was originally intended
to make adding new fields a natural extension mechanism for existing
elements. This codifies this into the spec and makes the behavior of the
llvm-symbolizer match. Extra fields are now warned about, but ignored,
rather than ignoring the whole element.
Reviewed By: mcgrathr
Differential Revision: https://reviews.llvm.org/D153821
This gives us more meaningful information when
`getAbbreviationDeclarationSet` fails. Right now only
`verifyAbbrevSection` actually uses the error that it returns, but the
other call sites could be rewritten to take advantage of the returned error.
Differential Revision: https://reviews.llvm.org/D153459
In preparation for removing the `#include "llvm/ADT/StringExtras.h"`
from the header to source file of `llvm/Support/Error.h`, first add in
all the missing includes that were previously included transitively
through this header.
There is a minor behavior difference that is not worth testing for the obsoleted
format. Previously, llvm-dwarfdump considers .zdebug_info as a debug section but
does not decompress it, leading to a warning when the content cannot be parsed.
Now llvm-dwarfdump just ignores the section without a warning.
D106624 added a .dwo warning (when there are relocations) that may fire for
non-debug sections, e.g. `.rodata.dwo` when there is a data symbol foo in
-fdata-sections mode. Adjust it to only warn for .debug sections.
While here, change the diagnostic to be more conventional
https://llvm.org/docs/CodingStandards.html#error-and-warning-messages and use
the relocated section name instead of the relocation section name.
This change does not handle `.zdebug` (support was mostly removed from LLVM) or
`__debug` (Mach-O, no DWO support).
Reviewed By: ayermolo, HaohaiWen
Differential Revision: https://reviews.llvm.org/D153602