This commit introduces a helper function to DWARFAcceleratorTable::Entry
which follows DW_IDX_Parent attributes to returns the corresponding
parent Entry in the table.
It is tested by enhancing dwarfdump so that it now prints:
1. When data is corrupt.
2. When parent information is present, but the parent is not indexed.
3. The parent entry offset, when the parent is present and indexed. This
is printed in terms a real entry offset (the same that gets printed at
the start of each entry: "Entry @ 0x..."), instead of the encoded number
in the table (which is an offset from the start off the Entry list).
This makes it easy to visually inspect the dwarfdump and check what the
parent is.
This implements the ideas discussed in [1].
To summarize, this commit changes AsmPrinter so that it outputs
DW_IDX_parent information for debug_name entries. It will enable
debuggers to speed up queries for fully qualified types (based on a
DWARFDeclContext) significantly, as debuggers will no longer need to
parse the entire CU in order to inspect the parent chain of a DIE.
Instead, a debugger can simply take the parent DIE offset from the
accelerator table and peek at its name in the debug_info/debug_str
sections.
The implementation uses two types of DW_FORM for the DW_IDX_parent
attribute:
1. DW_FORM_ref4, which points to the accelerator table entry for the
parent.
2. DW_FORM_flag_present, when the entry has a parent that is not in the
table (that is, the parent doesn't have a name, or isn't allowed to be
in the table as per the DWARF spec). This is space-efficient, since it
takes 0 bytes.
The implementation works by:
1. Changing how abbreviations are encoded (so that they encode which
form, if
any, was used to encode IDX_Parent)
2. Creating an MCLabel per accelerator table entry, so that they may be
referred by IDX_parent references.
When all patches related to this are merged, we are able to show that
evaluating an expression such as:
```
lldb --batch -o 'b CodeGenFunction::GenerateCode' -o run -o 'expr Fn' -- \
clang++ -c -g test.cpp -o /dev/null
```
is far faster: from ~5000 ms to ~1500ms.
Building llvm-project + clang with and without this patch, and looking
at its impact on object file size:
```
ls -la $(find build_stage2_Debug_idx_parent_assert_dwarf5 -name \*.cpp.o) | awk '{s+=$5} END {printf "%\047d\n", s}'
11,507,327,592
-la $(find build_stage2_Debug_no_idx_parent_assert_dwarf5 -name \*.cpp.o) | awk '{s+=$5} END {printf "%\047d\n", s}'
11,436,446,616
```
That is, an increase of 0.62% in total object file size.
Looking only at debug_names:
```
$stage1_build/bin/llvm-objdump --section-headers $(find build_stage2_Debug_idx_parent_assert_dwarf5 -name \*.cpp.o) | grep __debug_names | awk '{s+="0x"$3} END {printf "%\047d\n", s}'
440,772,348
$stage1_build/bin/llvm-objdump --section-headers $(find build_stage2_Debug_no_idx_parent_assert_dwarf5 -name \*.cpp.o) | grep __debug_names | awk '{s+="0x"$3} END {printf "%\047d\n", s}'
369,867,920
```
That is an increase of 19%.
DWARF Linkers need to be changed in order to support this. This commit
already brings support to "base" linker, but it does not attempt to
modify the parallel linker. Accelerator entries refer to the
corresponding DIE offset, and this patch also requires the parent DIE
offset -- it's not clear how the parallel linker can access this. It may
be obvious to someone familiar with it, but it would be nice to get help
from its authors.
[1]:
https://discourse.llvm.org/t/rfc-improve-dwarf-5-debug-names-type-lookup-parsing-speed/74151/
Allow the dumping of .dwo files contents to show up when dumping an
executable with split DWARF.
Currently if you run llvm-dwarfdump on a binary that has skeleton
compile units, you only see the skeleton compile units. Since the main
binary has the linked addresses it would be nice to be able to dump
DWARF from the .dwo files and how the resolved addresses instead of
showing the address index and "<unresolved>" in the output. This patch
adds an option that can be specified to dump the non skeleton DIEs named
--dwo.
Added the ability to use the following options with split dwarf as well:
--name <name>
--lookup <addr>
--debug-info <die-offset>
If there is no file name in the prologue of a line table, the verifier
will try to verify the file index, which will be set to 1 by default.
This will cause the DWARF verifier to throw an error even if there is no
error.
rdar://114476503
rdar://114343624
GNU addr2line supports lookup by symbol name in addition to the existing
address lookup. llvm-symbolizer starting from
e144ae54dcb96838a6176fd9eef21028935ccd4f supports lookup by symbol name.
This change extends this lookup with possibility to specify optional
offset.
Now the address for which source information is searched for can be
specified with offset:
llvm-symbolize --obj=abc.so "SYMBOL func_22+0x12"
It decreases the gap in features of llvm-symbolizer and GNU addr2line.
This lookup now is supported for code only.
Migrated from: https://reviews.llvm.org/D139859
Pull request: https://github.com/llvm/llvm-project/pull/75067
This is a follow up patch after .debug_names can now emit local type
unit entries when we compile with type units + DWARF5 + .debug_names.
The pull request that added this functionality was:
https://github.com/llvm/llvm-project/pull/70515
This patch makes sure that the DebugNamesDWARFIndex in LLDB will not
manually need to parse type units if they have a valid index. It also
fixes the index to be able to correctly extract name entries that
reference type unit DIEs. Added a test to verify things work as
expected.
llvm-gsymutil allows address ranges to overlap. There was a bug where if
we had debug info for a function with a range like [0x100-0x200) and a
symbol at the same start address yet with a larger range like
[0x100-0x300), we would randomly get either only information from the
first or second entry. This could cause lookups to fail due to the way
the binary search worked.
This patch makes sure that when lookups happen we find the first address
table entry that can match an address, and also ensures that we always
select the first FunctionInfo that could match. FunctionInfo entries are
sorted such that the most debug info rich entries come first. And if we
have two ranges that have the same start address, the smaller range
comes first and the larger one comes next. This patch also adds the
ability to iterate over all function infos with the same start address
to always find a range that contains the address.
Added a unit test to test this functionality that failed prior to this
fix and now succeeds.
Also fix an issue when dumping an entire GSYM file that has duplicate address entries where it used to always print out the binary search match for the FunctionInfo, not the actual data for the address index.
The DWARFUnitVector class lives inside of the DWARFContextState. Prior
to this fix a non const reference was being handed out to clients. When
fetching the DWO units, there used to be a "bool Lazy" parameter that
could be passed that would allow the DWARFUnitVector to parse individual
units on the fly. There were two major issues with this approach:
- not thread safe and causes crashes
- the accessor would check if DWARFUnitVector was empty and if not empty
it would return a partially filled in DWARFUnitVector if it was
constructed with "Lazy = true"
This patch fixes the issues by always fully parsing the DWARFUnitVector
when it is requested and only hands out a "const DWARFUnitVector &".
This allows the thread safety mechanism built into the DWARFContext
class to work corrrectly, and avoids the issue where if someone
construct DWARFUnitVector with "Lazy = true", and then calls an API that
partially fills in the DWARFUnitVector with individual entries, and then
someone accesses the DWARFUnitVector, they would get a partial and
incomplete listing of the DWARF units for the DWOs.
DWARF produced by LTO and BOLT can sometimes be broken where file
indexes are beyond the end of the line table's file list in the
prologue. This patch allows llvm-gsymutil to convert this DWARF without
crashing, and emits errors when:
line table contains entries with an invalid file index (line entry will
be removed) inline functions that have invalid DW_AT_call_file file
indexes when there are no line table entries for a function and we fall
back to making a single line table entry from the functions
DW_AT_decl_file/DW_AT_decl_line attributes, we make sure the
DW_AT_decl_file attribute is valid before emitting it.
Fix line table lookups in line tables with multiple lines with the same
address.
Compilers emit line tables that have multiple line table entries with
the same address. When doing lookups, we always need to use the last
line entry if a lookup address matches the address of one or more line
entries. This is because the size of an address range for a line uses
the next line entry to figure out how big the current line entry is. If
the next line entry has the same address, that means the current line
entry has a size of zero, so no bytes correspond to the line entry.
This patch ensures that lookups will always pick the last matching line
entry when the lookup address matches more than one line entry.
llvm/include/llvm/Support/VersionTuple.h doesn't need anything from
llvm/Support/Endian.h, but llvm/lib/DebugInfo/BTF/BTFParser.cpp relies
on a transitive inclusion of llvm/Support/Endian.h.
Recent versions of GNU binutils starting from 2.39 support symbol+offset
lookup in addition to the usual numeric address lookup. This change adds
symbol lookup to llvm-symbolize and llvm-addr2line.
Now llvm-symbolize behaves closer to GNU addr2line, - if the value specified
as address in command line or input stream is not a number, it is treated as
a symbol name. For example:
llvm-symbolize --obj=abc.so func_22
llvm-symbolize --obj=abc.so "CODE func_22"
This lookup is now supported only for functions. Specification with
offset is not supported yet.
This is a recommit of 2b27948783e4bbc1132d3220d8517ef62607b558, reverted
in 39fec5457c0925bd39f67f63fe17391584e08258 because the test
llvm/test/Support/interrupts.test started failing on Windows. The test was
changed in 18f036d0105589c3175bb51a518c5d272dae61e2 and is also updated in
this commit.
Differential Revision: https://reviews.llvm.org/D149759
C++20 comes with std::erase to erase a value from std::vector. This
patch renames llvm::erase_value to llvm::erase for consistency with
C++20.
We could make llvm::erase more similar to std::erase by having it
return the number of elements removed, but I'm not doing that for now
because nobody seems to care about that in our code base.
Since there are only 50 occurrences of erase_value in our code base,
this patch replaces all of them with llvm::erase and deprecates
llvm::erase_value.
These files satisfy all of the following:
- misc-include-cleaner indicates that these files do not need
Endian.h.
- They do not mention "endian" anywhere.
- They do not include any *.inc or *.def, which could need
llvm::support::endian.
In ef762e5e7292, I shifted around where errors were reported when
failing to parse and/or validate DWARFUnitHeaders. When we are doing so
in DWARFContext::fixupIndex, the actual error message isn't prefixed
with `warning:` like it would be elsewhere (because of the way
`logAllUnhandledErrors` is implemented).
Instead of reporting the error directly through the DWARFContext passed
in as an argument, it would be more flexible to have extract return the
error and allow the caller to react appropriately.
This will be useful for using llvm's DWARFHeaderUnit from lldb which may
report header extraction errors through a different mechanism.
Previous to this fix, if we had a DW_TAG_subprogram that had a
DW_AT_linkage_name that was empty, it would attempt to use this name
which would cause an error to be emitted when saving the gsym file to
disk:
error: DWARF conversion failed: : attempted to encode invalid
FunctionInfo object
This patch fixes this issue and adds a unit test case.
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an
enum. This patch replaces support::{big,little,native} with
llvm::endianness::{big,little,native}.
Note that llvm::support::endianness has been renamed to
llvm::endianness while becoming an enum class as opposed to an enum.
This patch replaces llvm::support::{big,little,native} with
llvm::endianness::{big,little,native}.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can use the shorter form. This patch replaces
support::endianness::{big,little,native} with
llvm::endianness::{big,little,native}.
Right now DWARFContext for DWO/DWP that is created is not thread safe.
Changed it so that thread safety is inherited from the main
binary DWARFContext.
For now, data location expression is hard coded to little endian. We are
going to support sanitizers on AIX which is big endian. Support big
endian too in the data location expression parser of llvm-symbolizer.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can use the shorter form. This patch replaces
llvm::support::endianness with llvm::endianness.
Now that llvm::support::endianness has been renamed to
llvm::endianness, we can directly get endianness from the llvm
namespace. We don't need to go through support.
Changed so that when Abbrev code is printed out for entry it is done in
the same
way as in Abbrev table.
Once letters are present in a hex number in abbrev table they will be
lower case,
and in the Entry upper case. Which makes FIleCheck Pattern recognition
fail.
Example in: llvm/test/tools/llvm-dwarfdump/X86/debug-names-misaligned.s
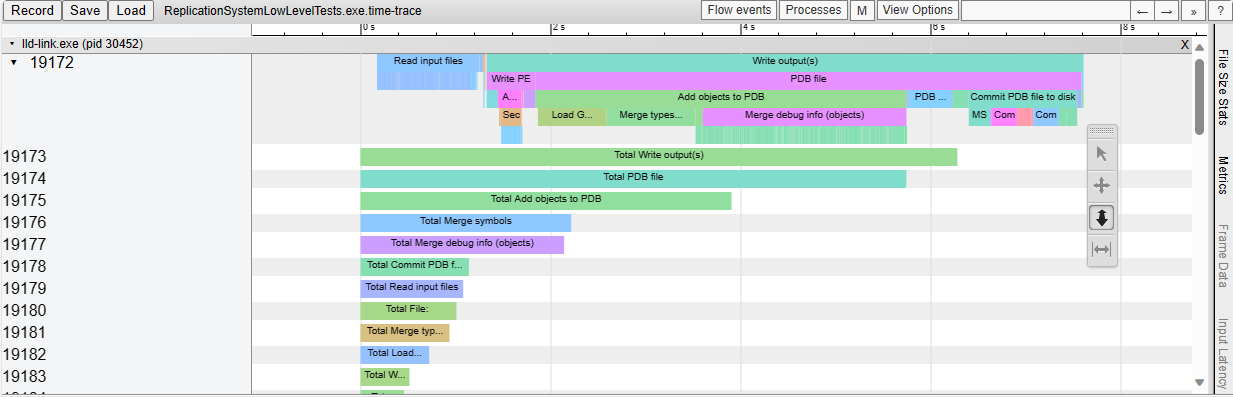
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable: