This expresses better what the class actually does, and it reduces the
number of
`Context`s that we have in the codebase.
A deprecated alias `ControlFlowContext` is available from the old
header.
The CFG orders the blocks of loop bodies before those of loop successors
(both numerically, and in the successor order of the loop condition
block). So, RPO necessarily reverses that order, placing the loop
successor *before* the loop body. For many analyses, particularly those
that converge to a fixpoint, this results in potentially significant
extra work, because loop successors will necessarily need to be
reconsidered once the algorithm has reached a fixpoint on the loop body.
This definition of CFG graph traits reverses the order of children, so
that loop bodies will come first in an RPO. Then, the algorithm can
fully evaluate the loop and only then consider successor blocks.
In particular, it's important that we create the "fallback" atomic at
this point
(which we produce if the transfer function didn't produce a value for
the
expression) so that it is placed in the correct environment.
Previously, we processed the terminator condition in the
`TerminatorVisitor`,
which put the fallback atomic in a copy of the environment that is
produced as
input for the _successor_ block, rather than the environment for the
block
containing the expression for which we produce the fallback atomic.
As a result, we produce different fallback atomics every time we process
the
successor block, and hence we don't have a consistent representation of
the
terminator condition in the flow condition.
This patch includes a test (authored by ymand@) that fails without the
fix.
In particular, it's important that we create the "fallback" atomic at
this point
(which we produce if the transfer function didn't produce a value for
the
expression) so that it is placed in the correct environment.
Previously, we processed the terminator condition in the
`TerminatorVisitor`,
which put the fallback atomic in a copy of the environment that is
produced as
input for the _successor_ block, rather than the environment for the
block
containing the expression for which we produce the fallback atomic.
As a result, we produce different fallback atomics every time we process
the
successor block, and hence we don't have a consistent representation of
the
terminator condition in the flow condition.
This patch includes a test (authored by ymand@) that fails without the
fix.
Previously, post-visit state changes were indistinguishable from
ordinary
iterations, which could give a confusing picture of how many iterations
a block
needs to converge.
Now, post-visit state changes are marked with "post-visit" instead of an
iteration number:
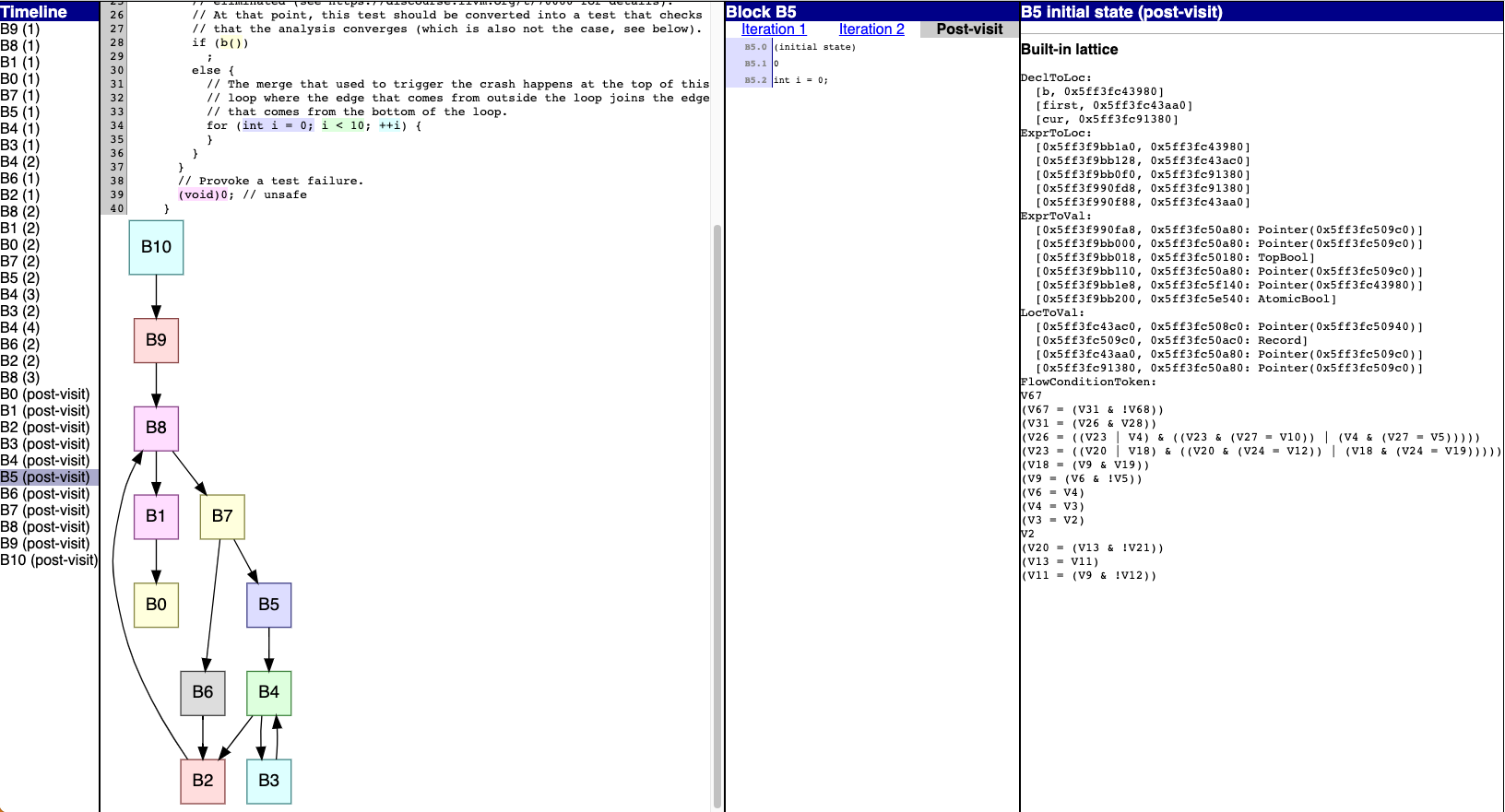)
This will eliminate the need for more pass-through APIs. Also replace pass-through usages with this exposure.
Reviewed By: ymandel, gribozavr2, xazax.hun
Differential Revision: https://reviews.llvm.org/D149464
With -dataflow-log=/dir we will write /dir/0.html etc for each
function analyzed.
These files show the function's code and CFG, and the path through
the CFG taken by the analysis. At each analysis point we can see the
lattice state.
Currently the lattice state dump is not terribly useful but we can
improve this: showing values associated with the current Expr,
simplifying flow condition, highlighting changes etc.
(Trying not to let this patch scope-creep too much, so I ripped out the
half-finished features)
Demo: 9718fdd484/analysis.html
Differential Revision: https://reviews.llvm.org/D146591
The goal is to be able to understand how the analysis executes, and what its
incremental and final findings are, by enabling logging and reading the logs.
This should include both framework and analysis-specific information.
Ad-hoc printf-debugging doesn't seem sufficient for my understanding, at least.
Being able to check in logging, turn it on in a production binary, and quickly
find particular analysis steps within complex functions seem important.
This can be enabled programmatically through DataflowAnalysisOptions, or
via the flag -dataflow-log. (Works in unittests, clang-tidy, standalone
tools...)
Important missing pieces here:
- a logger implementation that produces an interactive report (HTML file)
which can be navigated via timeline/code/CFG.
(I think the Logger interface is sufficient for this, but need to prototype).
- display of the application-specific lattice
- more useful display for the built-in environment
(e.g. meaningful & consistent names for values, hiding redundant variables in
the flow condition, hiding unreachable expressions)
Differential Revision: https://reviews.llvm.org/D144730