When marking symbols as having their address taken, we can have the
sitaution where we have the address taken of a weak symbol. If there's
no strong definition of the symbol, the symbol ends up as an absolute
symbol with the value null. In those cases, we don't have any Chunk.
Skip such symbols from the cfguard tables.
This fixes https://github.com/llvm/llvm-project/issues/78619.
This shouldn't have any user visible effect, but makes the logic within
the linker implementation more explicit.
Note how DWARF debug info sections were retained even if enabling a link
with PDB info only; that behaviour is preserved.
After #71433, lld-link is able to always generate build id even when PDB
is not generated.
This adds the `__buildid` symbol to points to the start of 16 bytes guid
(which is after `RSDS`) and allows profile runtime to access it and dump
it to raw profile.
[RFC](https://discourse.llvm.org/t/rfc-add-build-id-flag-to-lld-link/74661)
Before, lld-link only generate the debug directory containing guid when
generating PDB with the hash of PDB content.
With this change, lld-link can generate the debug directory when only
`/build-id` is given:
1. If generating PDB, `/build-id` is ignored. Same behaviour as before.
2. Not generating PDB, using hash of the binary.
- Not under MinGW, the debug directory is still in `.rdata` section.
- Under MinGW, place the debug directory into new `.buildid` section.
ARM64EC needs to handle both ARM and x86_64 exception tables. This is
achieved by separating their chunks and sorting them separately.
EXCEPTION_TABLE directory references x86_64 variant, while ARM variant
is exposed using CHPE metadata, which references
__arm64x_extra_rfe_table and __arm64x_extra_rfe_table_size symbols.
Boundaries between code chunks of different architecture are always
aligned. 0x1000 seems to be a constant, this does not seem to be
affected by any command line alignment argument.
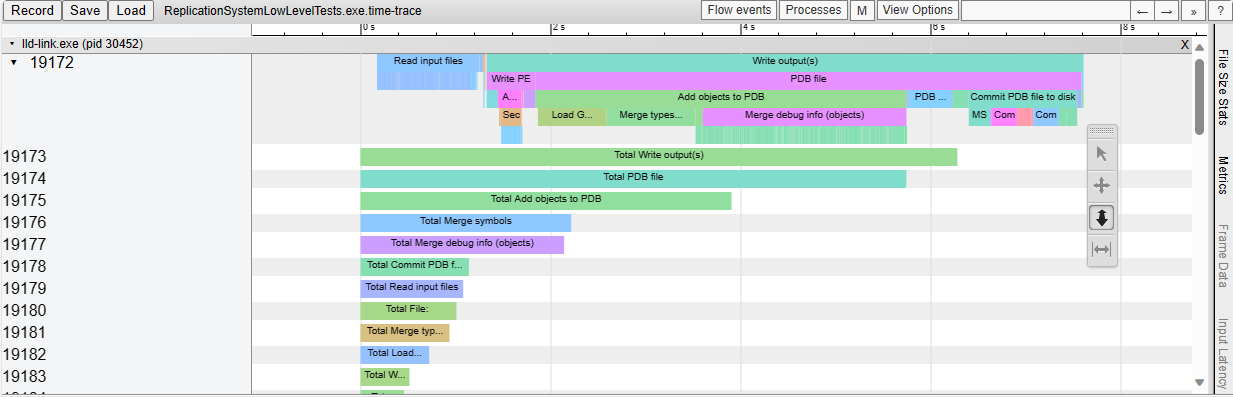
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
This adds very minimal support for ARM64EC/ARM64X targets,
just enough for interesting test cases. Next patches in the
series extend llvm-objdump and llvm-readobj to provide
better tests. Those will also be useful for testing further
ARM64EC LLD support.
Differential Revision: https://reviews.llvm.org/D149086
This reverts part of commit 44363f2ff2736e4edf4a260f442b513ceac661fc.
Fixup for NO symbol table test has been reserved.
Reviewed By: wxiao3
Differential Revision: https://reviews.llvm.org/D151417
MS link accepts *.obj with ehcont bit set only. LLD should match this
behavoir too.
Reviewed By: rnk
Differential Revision: https://reviews.llvm.org/D150508
It doesn't make sense on ARM and using default 0 fill is compatible
with MSVC.
(It's more noticeable ARM64EC targets, where additional padding mixed
with alignment is used for entry thunk association, so there are more
gaps).
Reviewed By: mstorsjo
Differential Revision: https://reviews.llvm.org/D145962
By using emplace_back, as well as converting some loops to for-each, we can do more efficient vectorization.
Make copy constructor for TemporaryFile noexcept.
Reviewed By: #lld-macho, int3
Differential Revision: https://reviews.llvm.org/D139552
Similar to how `makeArrayRef` is deprecated in favor of deduction guides, do the
same for `makeMutableArrayRef`.
Once all of the places in-tree are using the deduction guides for
`MutableArrayRef`, we can mark `makeMutableArrayRef` as deprecated.
Differential Revision: https://reviews.llvm.org/D141814
For each symbol in a /delayloaded library, lld injects a small piece of
code to handle the symbol lazy loading. This code doesn't have unwind
information, which may be troublesome.
Provide these information for AMD64.
Thanks to Yannis Juglaret <yjuglaret@mozilla.com> for contributing the
unwinding info and for his support while crafting this patch.
Fix#59639
Differential Revision: https://reviews.llvm.org/D141691
string_view has a slightly weaker contract, which only specifies whether
the value is bigger or smaller than 0. Adapt users accordingly and just
forward to the standard function (that also compiles down to memcmp)
This reverts commit 7370ff624d217b0f8f7512ca5b651a9b8095a411.
(and 47fb8ae2f9a4075de05433ef24f459b6befd1730).
This commit broke the symbol type in import libraries generated
for mingw autoexported symbols, when the source files were built
with LTO. I'll commit a testcase that showcases this issue after
the revert.
Absolute symbol should contain its absolute value, but LLD had been
writing its RVA instead. Write its VA instead.
DefinedSynthetic were being skipped before with the reasoning "Relative
symbols are unrepresentable in a COFF symbol table", which is only true
if the RVA points to outside of a section. LLD does create synthetic
symbols which points to actual data chunks (typical for symbols embedded
into the load config directory). Write these symbols to the COFF symbol
table too.
Reviewed By: mstorsjo
Differential Revision: https://reviews.llvm.org/D134462
Control Flow Guard requires specific flags and VA's be included in the
load config directory to be functional. In case CFGuard is enabled via
linker flags, we can check to make sure this is the case and give the
user a warning if otherwise.
MSVC provides a proper `_load_config_used` by default, so this is more
relevant for the MinGW target in which current versions of mingw-w64
does not provide this symbol.
The checks (only if CFGuard is enabled) include:
- The `_load_config_used` struct shall exist.
- Alignment of the `_load_config_used` struct (shall be aligned to
pointer size.)
- The `_load_config_used` struct shall be large enough to contain the
required fields.
- The values of the following fields are checked against the expected
values:
- GuardCFFunctionTable
- GuardCFFunctionCount
- GuardFlags
- GuardAddressTakenIatEntryTable
- GuardAddressTakenIatEntryCount
- GuardLongJumpTargetTable
- GuardLongJumpTargetCount
- GuardEHContinuationTable
- GuardEHContinuationCount
Reviewed By: rnk
Differential Revision: https://reviews.llvm.org/D133099
Import thunks themselves contain a jump or branch, which is code by
nature. Therefore the import thunk symbol should be marked as function
type in the symbol table to help with debugging.
The `__imp_` import symbol associated to the import thunk is also useful
for debugging. However, when the import symbol isn't directly referenced
outside of the import thunk, it doesn't normally get added to the symbol
table. This change teaches LLD to add the import symbol explicitly.
Reviewed By: mstorsjo
Differential Revision: https://reviews.llvm.org/D134169
Bug: An assertion fails:
Assertion failed: isa<To>(Val) && "cast<Ty>() argument of incompatible type!",
file C:\Users\<user>\prog\llvm\llvm-git-lld-bug\llvm\include\llvm/Support/Casting.h, line 578
Bug is triggered, if
- a map file is requested with /MAP, and
- Architecture is ARMv7, Thumb, and
- a relative jump (branch instruction) is greater than 16 MiB (2^24)
The reason for the Bug is:
- a Thunk is created for the jump
- a Symbol for the Thunk is created
- of type `DefinedSynthetic`
- in file `Writer.cpp`
- in function `getThunk`
- the Symbol has no name
- when creating the map file, the name of the Symbol is queried
- the function `Symbol::computeName` of the base class `Symbol`
casts the `this` pointer to type `DefinedCOFF` (a derived type),
but the acutal type is `DefinedSynthetic`
- The in the llvm::cast an assertion fails
Changes:
- Modify regression test to trigger this bug
- Give the symbol pointing to the thunk a name, to fix the bug
- Add assertion, that only DefinedCOFF symbols are allowed to have an
empty name, when the constructor of the base class Symbol is executed
Reviewed By: rnk
Differential Revision: https://reviews.llvm.org/D133201
This also modifies llvm-readobj to be more future-proof when printing
the guard FIDs table by calculating the entry size correctly according
to MS docs.
Reviewed By: rnk
Differential Revision: https://reviews.llvm.org/D132924
This reverts commit 9ffeaaa0ea54307db309104696a0b6cce6ddda38.
This fixes debugging large executables with lldb and gdb.
When StringTableBuilder is used, the string offsets for any string
can point anywhere in the string table - while previously, all strings
were inserted in order (without deduplication and tail merging).
For symbols, there's no complications in encoding the string offset;
the offset is encoded as a raw 32 bit binary number in half of the
symbol name field.
For sections, the string table offset is written as
"/<decimaloffset>", but if the decimal offset would be larger than
7 digits, it's instead written as "//<base64offset>". Tools that
operate on object files can handle the base64 offset format, but
apparently neither lldb nor gdb expect that syntax when locating the
debug information section. Prior to the reverted commit, all long
section names were located at the start of the string table, so
their offset never exceeded the range for the decimal syntax.
Just reverting this change for now, as the actual benefit from it
was fairly modest.
Longer term, lld could write all long section names unoptimized
at the start of the string table, followed by all the strings for
symbol names, with deduplication and tail merging. And lldb and
gdb could be fixed to handle sections with the base64 offset syntax.
This fixes https://github.com/mstorsjo/llvm-mingw/issues/289.
So far, we sort all discardable sections at the end, with only some
extra logic to make sure that the .reloc section is at the start
of that group of sections. But if there are other discardable
sections, other than .reloc, they must also be ordered before
.debug_* sections, to avoid leaving gaps if the executable is
stripped.
(Stripping executables doesn't remove all discardable sections,
only the ones named .debug_*).
Rust binaries seem to include a .rmeta section, which is marked
discardable. This fixes stripping such binaries if built with
dwarf debug info included.
This fixes issues observed in MSYS2 in
https://github.com/msys2/MINGW-packages/pull/10555.
Differential Revision: https://reviews.llvm.org/D120805
This does tail merging (and deduplication) of the strings.
On a statically linked clang.exe, this shrinks the ~17 MB string
table by around 0.5 MB. This adds ~160 ms to the linking time
which originally was around 950 ms.
For cases where `-debug:symtab` or `-debug:dwarf` isn't set, the
string table is only used for long section names, where this
shouldn't make any difference at all.
Differential Revision: https://reviews.llvm.org/D120677
The previous code used an unbounded sprintf, which in theory can
overflow, writing either the null terminator or the last digits
into the next struct member.
In practice, in LLD, all long section names are written sequentially
first at the start of the string table, followed by all the long
symbol names. Due to this, even if the total string table would
end up large, the long section names have fairly short offsets,
which is why this hasn't been an issue in practice.
I don't think it's worth trying to write a test that produces an
executable with enough long section names to make the section names
themselves exceed 10^6 bytes, which is currently necessary to trigger
faults with the previous form.
Differential Revision: https://reviews.llvm.org/D120676